* Clustering Overview.
§ 클러스터링 개념 ?
> 밀접히 관련된 사물, 사람, 아이디어 들의 그룹을 찾는 기법.
즉 주어진 Data Set 내에서 유사항목을 가진 그룹을 검출 하는 것.> 올바른 답을 찾는 것이 아니고 데이터 집합내에서 구조를 발견하는데 목적이 있음.
> 구분하려고 하는 각 class에 대한 아무런 지식이 없는 상태에서
분류(classify)하는 것이므로 자율학습 (Unsupervised Learning)에 해당한다.> sample에 대한 지식없이 similarity(유사도)에 근거하여 cluster들을 구분한다.
§ 클러스터링 !
> 패턴 공간에 주어진 유한 개의 패턴들이 서로 가깝게 모여서 무리를 이루고 있는
패턴 집합을 cluster(군집)라하고, 이 cluster들을 무리지어 나가는 처리 과정을 clustering 이라 한다.
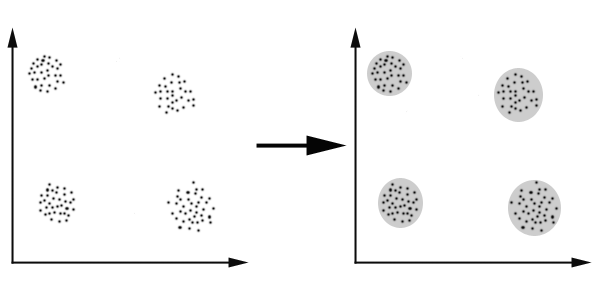
* 유사도
clustering은 하나의 data set을 여러개의 부분집합(clusters)으로 분할하는 것을 의미하며, 그때 각 부분집합에 있는 데이터는 몇가지의 공통된 특징(trait)을 공유한다. 그것은 몇가지 거리 측정법을 사용하여 유사도(similarity or proximity)를 계산함으로써 이루어진다. 예를들면 Euclidean distance, Mahalanobis distance, Lance-Williams distance, Hamming distance 등이 사용된다.
* 분류.
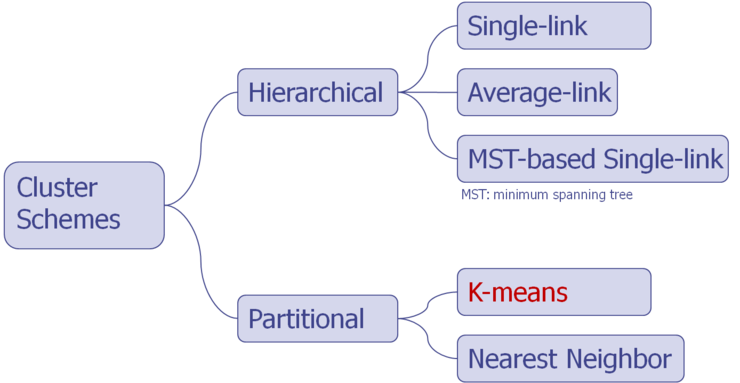
데이터 클러스터링은 크게 두가지, hierarchical clustering과 partitional clustering으로 나눌 수 있다.
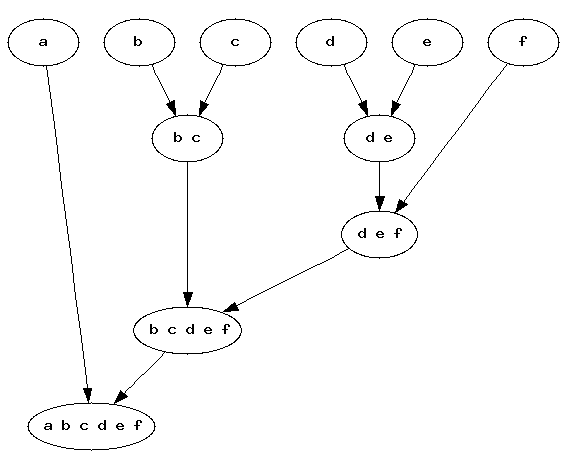
§ Hierarchical Clustering
> 각 요소들로부터 시작한 클러스터들이 계층구조를 이루는 Tree를 형성한다.
> agglomerative(bottom-up) 또는 divisive(top-down)으로 나누어 볼 수 있다.
> Tree에 한쪽 끝에는 각각의 요소가 있고 다른쪽 끝에는 모든 요소를 가지는 단하나에 클러스터가 있다.
§ Partitional Clustering
> cluster의 계층을 고려하지 않고 평면적으로 clustering하는 방법.
> 일반적으로 미리 몇 개의 cluster로 나누어 질 것이라고 예상하고 cluster를 개수를 정하는 것.
§ Algorithms
> Single-link : 클러스터 내의 여러 점들 중 두 개의 점의 인접성이 가장 작은 것들 부터 병합하는 알고리즘.
> Average-link algorithm : 클러스터 내의 여러 점들간의 거리 평균에 대한 인접성이
가장 작은 것들 부터 병합하는 알고리즘.> K-means algorithm : 무작위로 선정된 k개의 중심점을 선정하고 그 점에서
가장 근접한 항목들을 클러스터에 할당. 할당 후에는할당된 모든 노드들의 평균 위치로 중심점을 이동시키고 재할당을 수행.
실행시간이 빠르다는 장점이 있으나 적절한 초기 입력값 K의 선정이 중요
출처 : http://blog.naver.com/albertx?Redirect=Log&logNo=100191595217
'Fundamental > Technical ' 카테고리의 다른 글
| k-medoids 기법 : 대표 객체기반 기법 (데이터마이닝) (0) | 2014.05.12 |
|---|---|
| k-means 기법 (데이터마이닝) (0) | 2014.05.12 |
| Network 용어정리 (0) | 2014.04.22 |
| 루틴과 서브루틴 (routine and subroutine) (0) | 2014.04.16 |
| 외래어 / 고유명사 표기 사전 (0) | 2014.04.16 |
댓글