This is a guest post by Yukinori Koide, the head of development for the Newspass department at Gunosy.
Gunosy, in their own words: Gunosy is a news curation application that covers a wide range of topics, such as entertainment, sports, politics, and gourmet news. The application has been installed more than 20 million times. Gunosy aims to provide people with the content they want without the stress of dealing with a large influx of information. We analyze user attributes, such as gender and age, and past activity logs like click-through rate (CTR). We combine this information with article attributes to provide trending, personalized news articles to users.
In this post, I’ll show you how to process user activity logs in real time using Amazon Kinesis Data Firehose, Amazon Kinesis Data Analytics, and related AWS services.
Why does Gunosy need real-time processing?
Users need fresh and personalized news. There are two constraints to consider when delivering appropriate articles:
- Time: Articles have freshness—that is, they lose value over time. New articles need to reach users as soon as possible.
- Frequency (volume): Only a limited number of articles can be shown. It’s unreasonable to display all articles in the application, and users can’t read all of them anyway.
To deliver fresh articles with a high probability that the user is interested in them, it’s necessary to include not only past user activity logs and some feature values of articles, but also the most recent (real-time) user activity logs.
We optimize the delivery of articles with these two steps.
- Personalization: Deliver articles based on each user’s attributes, past activity logs, and feature values of each article—to account for each user’s interests.
- Trends analysis/identification: Optimize delivering articles using recent (real-time) user activity logs—to incorporate the latest trends from all users.
Optimizing the delivery of articles is always a cold start. Initially, we deliver articles based on past logs. We then use real-time data to optimize as quickly as possible. In addition, news has a short freshness time. Specifically, day-old news is past news, and even the news that is three hours old is past news. Therefore, shortening the time between step 1 and step 2 is important.
To tackle this issue, we chose AWS for processing streaming data because of its fully managed services, cost-effectiveness, and so on.
Solution
The following diagrams depict the architecture for optimizing article delivery by processing real-time user activity logs
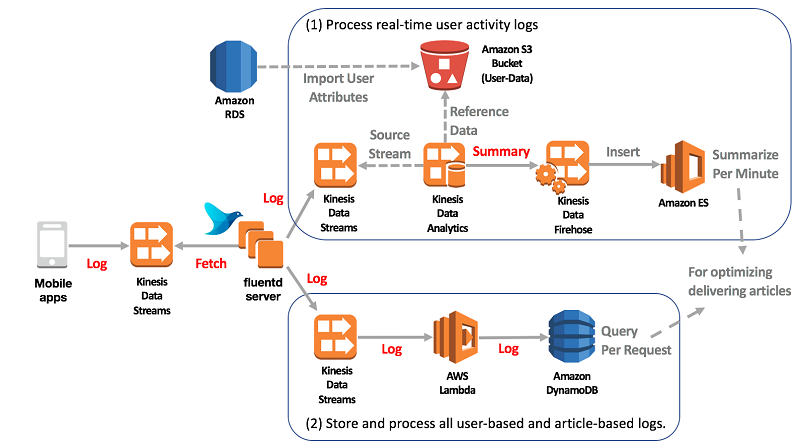

There are three processing flows:
- Process real-time user activity logs.
- Store and process all user-based and article-based logs.
- Execute ad hoc or heavy queries.
In this post, I focus on the first processing flow and explain how it works.
Process real-time user activity logs
The following are the steps for processing user activity logs in real time using Kinesis Data Streams and Kinesis Data Analytics.
- The Fluentd server sends the following user activity logs to Kinesis Data Streams:
{"article_id": 12345, "user_id": 12345, "action": "click"} {"article_id": 12345, "user_id": 12345, "action": "impression"} ...
- Map rows of logs to columns in Kinesis Data Analytics.

- Set the reference data to Kinesis Data Analytics from Amazon S3.
a. Gunosy has user attributes such as gender, age, and segment. Prepare the following CSV file (user_id, gender, segment_id) and put it in Amazon S3:
101,female,1 102,male,2 103,female,3 ...
b. Add the application reference data source to Kinesis Data Analytics using the AWS CLI:
$ aws kinesisanalytics add-application-reference-data-source \ --application-name <my-application-name> \ --current-application-version-id <version-id> \ --reference-data-source '{ "TableName": "REFERENCE_DATA_SOURCE", "S3ReferenceDataSource": { "BucketARN": "arn:aws:s3:::<my-bucket-name>", "FileKey": "mydata.csv", "ReferenceRoleARN": "arn:aws:iam::<account-id>:role/..." }, "ReferenceSchema": { "RecordFormat": { "RecordFormatType": "CSV", "MappingParameters": { "CSVMappingParameters": {"RecordRowDelimiter": "\n", "RecordColumnDelimiter": ","} } }, "RecordEncoding": "UTF-8", "RecordColumns": [ {"Name": "USER_ID", "Mapping": "0", "SqlType": "INTEGER"}, {"Name": "GENDER", "Mapping": "1", "SqlType": "VARCHAR(32)"}, {"Name": "SEGMENT_ID", "Mapping": "2", "SqlType": "INTEGER"} ] } }'
This application reference data source can be referred on Kinesis Data Analytics.
- Run a query against the source data stream on Kinesis Data Analytics with the application reference data source.
a. Define the temporary stream named TMP_SQL_STREAM.
CREATE OR REPLACE STREAM "TMP_SQL_STREAM" ( GENDER VARCHAR(32), SEGMENT_ID INTEGER, ARTICLE_ID INTEGER );
b. Insert the joined source stream and application reference data source into the temporary stream.
CREATE OR REPLACE PUMP "TMP_PUMP" AS INSERT INTO "TMP_SQL_STREAM" SELECT STREAM R.GENDER, R.SEGMENT_ID, S.ARTICLE_ID, S.ACTION FROM "SOURCE_SQL_STREAM_001" S LEFT JOIN "REFERENCE_DATA_SOURCE" R ON S.USER_ID = R.USER_ID;
c. Define the destination stream named DESTINATION_SQL_STREAM.
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( TIME TIMESTAMP, GENDER VARCHAR(32), SEGMENT_ID INTEGER, ARTICLE_ID INTEGER, IMPRESSION INTEGER, CLICK INTEGER );
d. Insert the processed temporary stream, using a tumbling window, into the destination stream per minute.
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM ROW_TIME AS TIME, GENDER, SEGMENT_ID, ARTICLE_ID, SUM(CASE ACTION WHEN 'impression' THEN 1 ELSE 0 END) AS IMPRESSION, SUM(CASE ACTION WHEN 'click' THEN 1 ELSE 0 END) AS CLICK FROM "TMP_SQL_STREAM" GROUP BY GENDER, SEGMENT_ID, ARTICLE_ID, FLOOR("TMP_SQL_STREAM".ROWTIME TO MINUTE);
The results look like the following:

- Insert the results into Amazon Elasticsearch Service (Amazon ES).
- Batch servers get results from Amazon ES every minute. They then optimize delivering articles with other data sources using a proprietary optimization algorithm.
How to connect a stream to another stream in another AWS Region
When we built the solution, Kinesis Data Analytics was not available in the Asia Pacific (Tokyo) Region, so we used the US West (Oregon) Region. The following shows how we connected a data stream to another data stream in the other Region.

There is no need to continue containing all components in a single AWS Region, unless you have a situation where a response difference at the millisecond level is critical to the service.
Benefits
The solution provides benefits for both our company and for our users. Benefits for the company are cost savings—including development costs, operational costs, and infrastructure costs—and reducing delivery time. Users can now find articles of interest more quickly. The solution can process more than 500,000 records per minute, and it enables fast and personalized news curating for our users.
Conclusion
In this post, I showed you how we optimize trending user activities to personalize news using Amazon Kinesis Data Firehose, Amazon Kinesis Data Analytics, and related AWS services in Gunosy.
AWS gives us a quick and economical solution and a good experience.
If you have questions or suggestions, please comment below.
Additional Reading
If you found this post useful, be sure to check out Implement Serverless Log Analytics Using Amazon Kinesis Analyticsand Joining and Enriching Streaming Data on Amazon Kinesis.
About the Author

Yukinori Koide is the head of development for the Newspass department at Gunosy. He is working on standardization of provisioning and deployment flow, promoting the utilization of serverless and containers for machine learning and AI services. His favorite AWS services are DynamoDB, Lambda, Kinesis, and ECS.
'Industry 4.0 > Edge computing' 카테고리의 다른 글
| APACHE IGNITE VS REDIS (0) | 2020.12.22 |
|---|---|
| Azure에서 은행 시스템 클라우드 변환 (0) | 2020.11.23 |
| Level Up Your Games with Amazon Aurora (0) | 2020.11.23 |
| Webhooks - Facebook (0) | 2020.10.19 |
| JHipster란? (0) | 2020.10.19 |



댓글